LinkedHashMap是Map接口的哈希表和链接列表实现,具有可预知的迭代顺序。LinkedHashMap提供所有可选的映射操作,并允许使用null值和null键。
LinkedHashMap维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。
默认是按插入顺序排序,如果指定按访问顺序排序,那么调用get方法后,会将这次访问的元素移至链表尾部,不断访问可以形成按访问顺序排序的链表。此实现是线程非安全的。
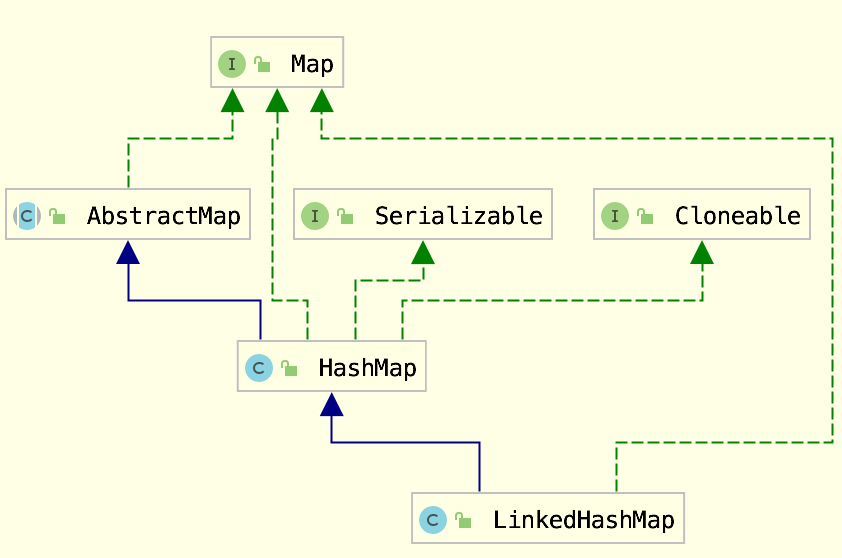
类图
LinkedHashMap继承于HashMap、底层使用哈希表与双向链表来保存所有元素。其基本操作与父类HashMap相似,它通过重写父类相关的方法,来实现自己的链接列表特性。
源码分析
Entry
LinkedHashMap采用的hash算法和HashMap相同,但是它重新定义了数组中保存的元素Entry,该Entry除了保存当前对象的引用外,还保存了其上一个元素before和下一个元素after的引用,从而在哈希表的基础上又构成了双向链接列表。
/**
* HashMap.Node subclass for normal LinkedHashMap entries. 继承HashMap.Node,并保留before,after引用
*/
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
/**
* The head (eldest) of the doubly linked list.双向链表头
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.双向链表尾
*/
transient LinkedHashMap.Entry<K,V> tail;
排序模式
LinkedHashMap定义了排序模式accessOrder,该属性为boolean型变量,对于访问顺序,为true;对于插入顺序,则为false。
/**
* The iteration ordering method for this linked hash map: true
* for access-order, false for insertion-order.
*/
final boolean accessOrder;
构造函数
其实就是调用的 HashMap 的构造方法,并初始化accessOrder的值。
public LinkedHashMap() {
super();//调用的 HashMap 的构造方法
accessOrder = false;
}
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
三个重要函数
在HashMap中有如下定义
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { }//访问结点后
void afterNodeInsertion(boolean evict) { }//插入节点后
void afterNodeRemoval(Node<K,V> p) { }//移除结点后
LinkedHashMap继承于HashMap,重新实现了这3个函数
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {//如果定义了accessOrder,那么就保证最近访问节点放到最后
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
我们从上面3个函数看出来,基本上都是为了保证双向链表中的节点次序或者双向链表容量所做的一些额外的事情,目的就是保持双向链表中节点的顺序要从eldest到youngest。
新条目插入到LinkedHashMap后,put和 putAll将调用afterNodeInsertion方法,注意到afterNodeInsertion方法中调用了removeEldestEntry,LinkedHashMap提供的removeEldestEntry(Map.Entry
eldest)方法,可以在每次添加新条目时移除最旧条目的实现程序,默认返回false(为fasle时此映射的行为将类似于正常映射,即永远不能移除最旧的元素)。
这种映射很适合构建LRU缓存,EhCache就是基于LinkedHashMap原理实现的,它允许映射通过删除旧条目来减少内存损耗。
例如:重写此方法,维持此映射只保存100个条目的稳定状态,在每次添加新条目时删除最旧的条目
private static final int MAX_ENTRIES = 100;
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > MAX_ENTRIES;
}
put方法
LinkedHashMap继承了HashMap 的 put 方法,对HashMap相应方法进行了重写。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);//LinkedHashMap 对其重写
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);//空实现,交给 LinkedHashMap 自己实现
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);//空实现,交给 LinkedHashMap 自己实现
return null;
}
get方法
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)//如果按照访问顺序排序,是则将当前的 Entry 移动到链表头部
afterNodeAccess(e);
return e.value;
}
ConcurrentModificationException
下面代码会抛出ConcurrentModificationException异常。
public class LRU {
private static final int MAX_SIZE = 3;
private LinkedHashMap<String, Integer> lru_cache = new LinkedHashMap<String, Integer>(MAX_SIZE, 0.1F, true) {
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return (lru_cache.size() > MAX_SIZE);
}
};
public Integer get1(String s) {
return lru_cache.get(s);
}
public void displayMap() {
for (String key : lru_cache.keySet()) {
System.out.println(lru_cache.get(key));//这里调用get时会修改LinkHashMap的结构,导致迭代发生异常
}
}
public void set(String s, Integer val) {
if (lru_cache.containsKey(s)) {
lru_cache.put(s, get1(s) + val);
} else {
lru_cache.put(s, val);
}
}
public static void main(String[] args) {
LRU lru = new LRU();
lru.set("Di", 1);
lru.set("Da", 1);
lru.set("Daa", 1);
lru.set("Di", 1);
lru.set("Di", 1);
lru.set("Daa", 2);
lru.set("Doo", 2);
lru.set("Doo", 1);
lru.set("Sa", 2);
lru.set("Na", 1);
lru.set("Di", 1);
lru.set("Daa", 1);
lru.displayMap();
}
}
运行代码,异常如下
1
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.LinkedHashMap$LinkedHashIterator.nextNode(LinkedHashMap.java:719)
at java.util.LinkedHashMap$LinkedKeyIterator.next(LinkedHashMap.java:742)
at com.perist.demo.collection.linkedhashmap.LRU.displayMap(LRU.java:23)
at com.perist.demo.collection.linkedhashmap.LRU.main(LRU.java:48)
我们看一下ConcurrentModificationException这个异常的官方描述
This exception may be thrown by methods that have detected concurrent
modification of an object when such modification is not permissible.
For example, it is not generally permissible for one thread to modify a Collection
while another thread is iterating over it. In general, the results of the
iteration are undefined under these circumstances. Some Iterator
implementations (including those of all the general purpose collection implementations
provided by the JRE) may choose to throw this exception if this behavior is
detected. Iterators that do this are known as fail-fast iterators,
as they fail quickly and cleanly, rather that risking arbitrary,
non-deterministic behavior at an undetermined time in the future.
Note that this exception does not always indicate that an object has
been concurrently modified by a different thread. If a single
thread issues a sequence of method invocations that violates the
contract of an object, the object may throw this exception. For
example, if a thread modifies a collection directly while it is
iterating over the collection with a fail-fast iterator, the iterator
will throw this exception.
Note that fail-fast behavior cannot be guaranteed as it is, generally
speaking, impossible to make any hard guarantees in the presence of
unsynchronized concurrent modification. Fail-fast operations
throw {@code ConcurrentModificationException} on a best-effort basis.
Therefore, it would be wrong to write a program that depended on this
exception for its correctness: {@code ConcurrentModificationException}
should be used only to detect bugs.
大概意思是下面两种情况会引发ConcurrentModificationException异常。
1 一个线程正在迭代集合时另一个线程修改了集合结构。(it is not generally permissible for one thread to modify a Collection while another thread is iterating over it.)
2 线程迭代时自己修改了集合结构。(If a single thread issues a sequence of method invocations that violates the contract of an object, the object may throw this exception. )
实例中不存在两个线程,很大可能是第二种情况引起的。
private LinkedHashMap<String, Integer> lru_cache = new LinkedHashMap<String, Integer>(MAX_SIZE, 0.1F, true) {
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return (lru_cache.size() > MAX_SIZE);
}
};
accessOrder为true,LinkHashMap是按照访问顺序排序的,所以调用get时会修改Map结构,导致了异常。
for (String key : lru_cache.keySet()) {
System.out.println(lru_cache.get(key));//这里调用get时会修改LinkHashMap的结构,导致迭代发生异常
}
改为下面形式可以避免ConcurrentModificationException吗?
for(Map.Entry<String, Integer> kv : lru_cache.entrySet()){//通过entryset获取时,不会修改LinkHashMap的结构,所以不会发生异常
System.out.println(kv.getKey() + ":" + kv.getValue());
}
但是,如果此时另一个线程正在添加或删除map结构,及修改map结构,还是会导致异常!
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
lru_cache.put(new Random().nextInt() + "", 1);
}
}
}).start();
for (Map.Entry<String, Integer> kv : lru_cache.entrySet()) {//lru_cache数据正在添加,还是会发生ConcurrentModificationException异常
System.out.println(kv.getKey() + ":" + kv.getValue());
}
使用forEach遍历时,如果同时map数据增加和减少,则会报错ConcurrentModificationException,因为forEach遍历时,是不允许map元素进行删除和增加。
正确遍历方式
Iterator<Map.Entry<String, Integer>> iterator = lru_cache.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, Integer> next = iterator.next();
System.out.println(next.getKey() + ":" + next.getValue());
}
为避免ConcurrentModificationException异常,遍历map时必须使用迭代器iteratorr,iterator在每一次迭代时都会调用hasNext()方法判断是否有下一个,是允许集合中数据增加和减少的。