如何遍历一棵树
有两种通用的遍历树的策略:
深度优先搜索(DFS)
DFS即Depth First Search,在这个策略中,我们采用深度作为优先级,以便从根开始一直到达某个确定的叶子,然后再返回根到达另一个分支。
深度优先搜索策略又可以根据根节点、左孩子和右孩子的相对顺序被细分为前序遍历,中序遍历和后序遍历。
宽度优先搜索(BFS)
BFS及Breadth First Search,我们按照高度顺序一层一层的访问整棵树,高层次的节点将会比低层次的节点先被访问到。
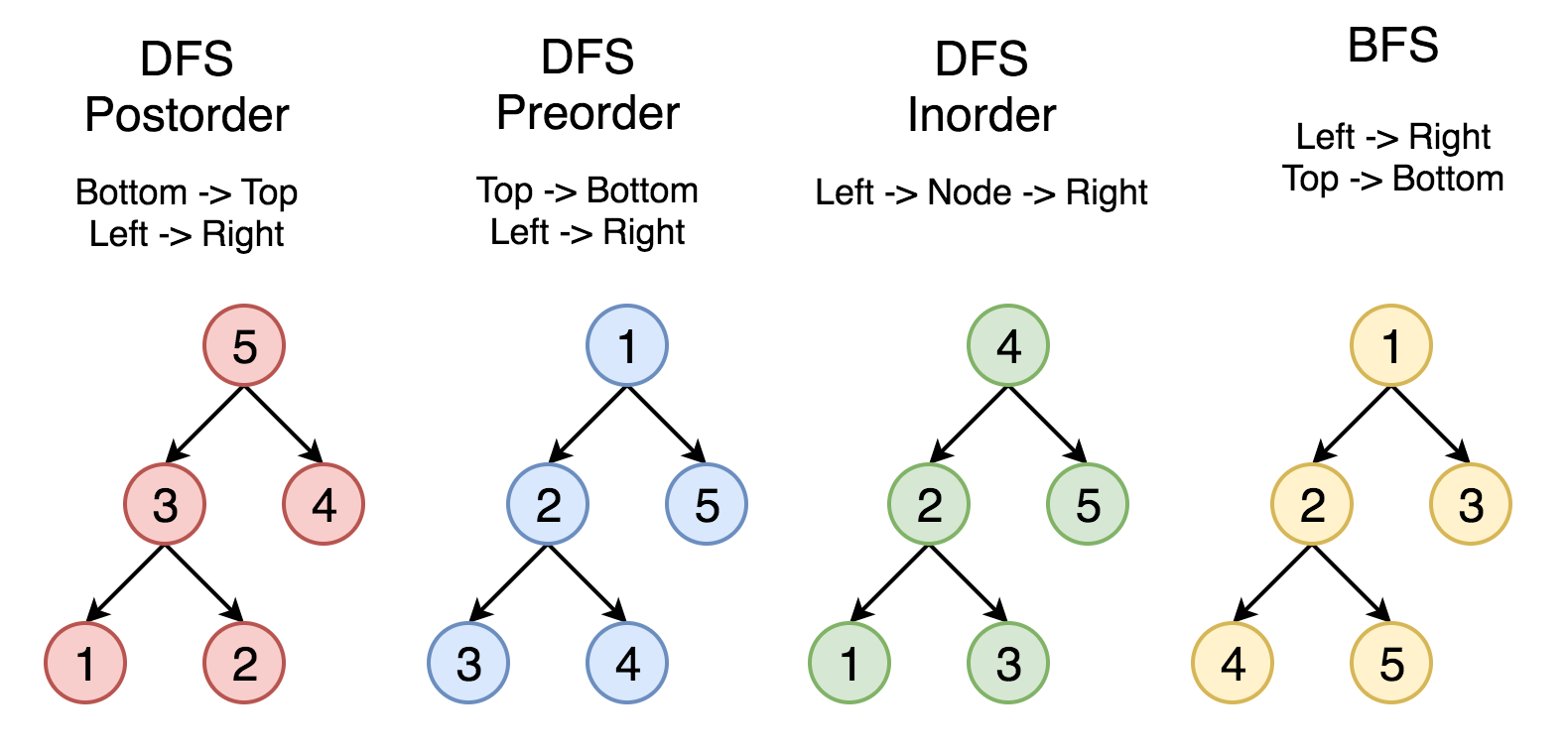
下图中的顶点按照访问的顺序编号,按照 1-2-3-4-5 的顺序来比较不同的策略。
首先给出二叉树节点类:
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) { val = x; }
}
先序遍历
递归
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> output = new LinkedList();
if(root==null){
return new LinkedList();
}
output.add(root.val);
output.addAll(preorderTraversal(root.left));
output.addAll(preorderTraversal(root.right));
return output;
}
非递归
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> output = new LinkedList();
if(root==null){
return new LinkedList();
}
Stack<TreeNode> stack = new Stack();
TreeNode node = root;
while(node!=null || !stack.isEmpty()){
while(node!=null){
output.add(node.val);
stack.push(node);
node = node.left;
}
if(!stack.isEmpty()){
node = stack.pop();
node =node.right;
}
}
return output;
}
中序遍历
递归
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> output = new LinkedList();
if(root ==null){
return new LinkedList();
}
output.addAll(inorderTraversal(root.left));
output.add(root.val);
output.addAll(inorderTraversal(root.right));
return output;
}
非递归
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> output = new LinkedList();
if(root==null){
return new LinkedList();
}
Stack<TreeNode> stack = new Stack();
TreeNode node = root;
while(node!=null || !stack.isEmpty()){
while(node !=null){
stack.push(node);
node =node.left;
}
if(!stack.isEmpty()){
node = stack.pop();
output.add(node.val);
node = node.right;
}
}
return output;
}
后序遍历
递归
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList();
if(root ==null){
return res;
}
res.addAll(postorderTraversal(root.left));
res.addAll(postorderTraversal(root.right));
res.add(root.val);
return res;
}
非递归
一种比较好理解的解法:
从根节点开始依次迭代,弹出栈顶元素输出到输出列表中,然后依次压入它的所有孩子节点,按照从上到下、从左至右的顺序依次压入栈中。
因为深度优先搜索后序遍历的顺序是从下到上、从左至右,所以需要将输出列表逆序输出。
public List<Integer> postorderTraversal(TreeNode root) {
LinkedList<TreeNode> stack = new LinkedList<>();
LinkedList<Integer> output = new LinkedList<>();
if (root == null) {
return output;
}
stack.add(root);
while (!stack.isEmpty()) {
TreeNode node = stack.pollLast();
output.addFirst(node.val);
if (node.left != null) {
stack.add(node.left);
}
if (node.right != null) {
stack.add(node.right);
}
}
return output;
}
另一种非递归解法:
lastVisit记录被访问的节点。
public List<Integer> postorderTraversal(TreeNode root) {
LinkedList<Integer> output = new LinkedList<>();
Stack<TreeNode> treeNodeStack = new Stack<TreeNode>();
TreeNode node = root;
TreeNode lastVisit = root;
while (node != null || !treeNodeStack.isEmpty()) {
while (node != null) {
treeNodeStack.push(node);
node = node.left;
}
node = treeNodeStack.peek();//查看当前栈顶元素
//如果其右子树也为空,或者右子树已经访问
//则可以直接输出当前节点的值
if (node.right == null || node.right == lastVisit) {
output.add(node.val);
treeNodeStack.pop();
lastVisit = node;
node = null;
} else {
//否则,继续遍历右子树
node = node.right;
}
}
return output;
}
DFS & BFS
DFS 遍历使用递归:
void dfs(TreeNode root) {
if (root == null) {
return;
}
dfs(root.left);
dfs(root.right);
}
BFS 遍历使用队列数据结构:
void bfs(TreeNode root) {
Queue<TreeNode> queue = new ArrayDeque<>();
queue.add(root);
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
if (node.left != null) {
queue.add(node.left);
}
if (node.right != null) {
queue.add(node.right);
}
}
}
虽然 DFS 与 BFS 都是将二叉树的所有结点遍历了一遍,但它们遍历结点的顺序不同。
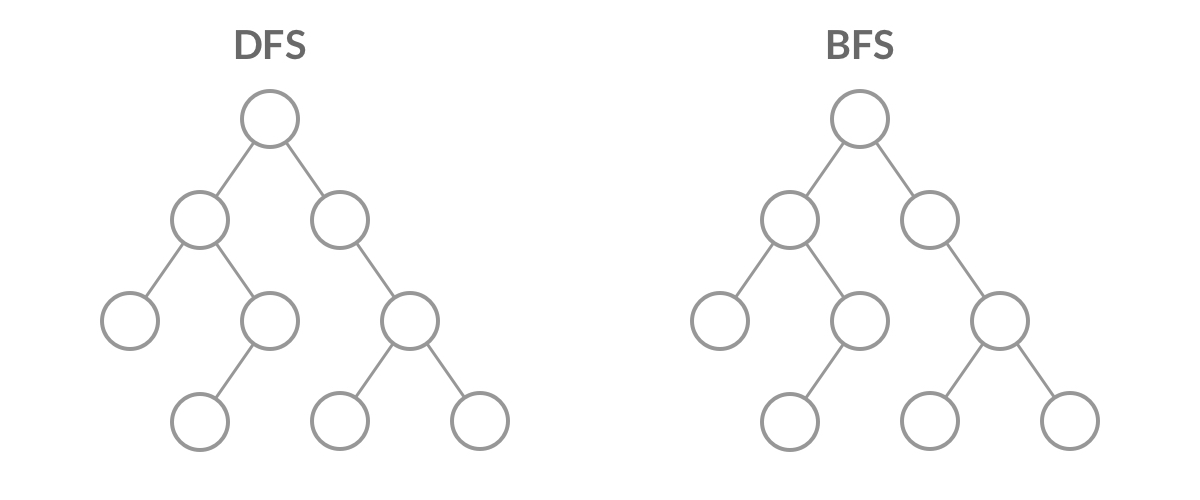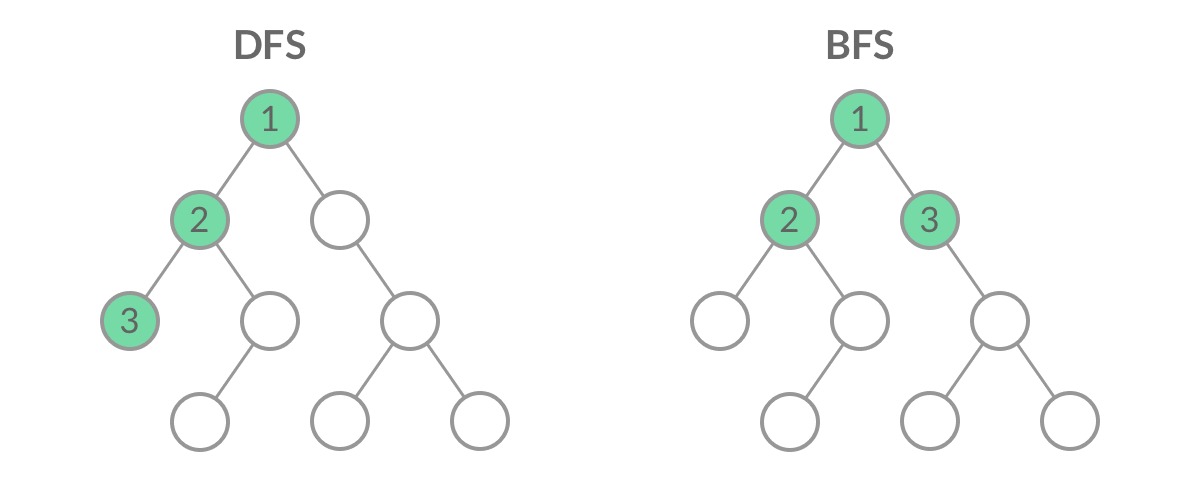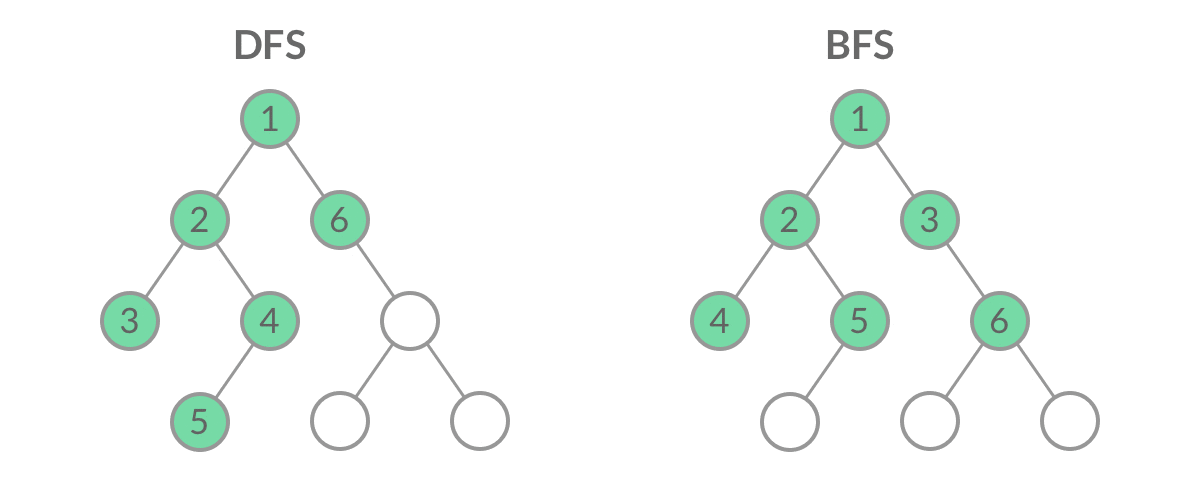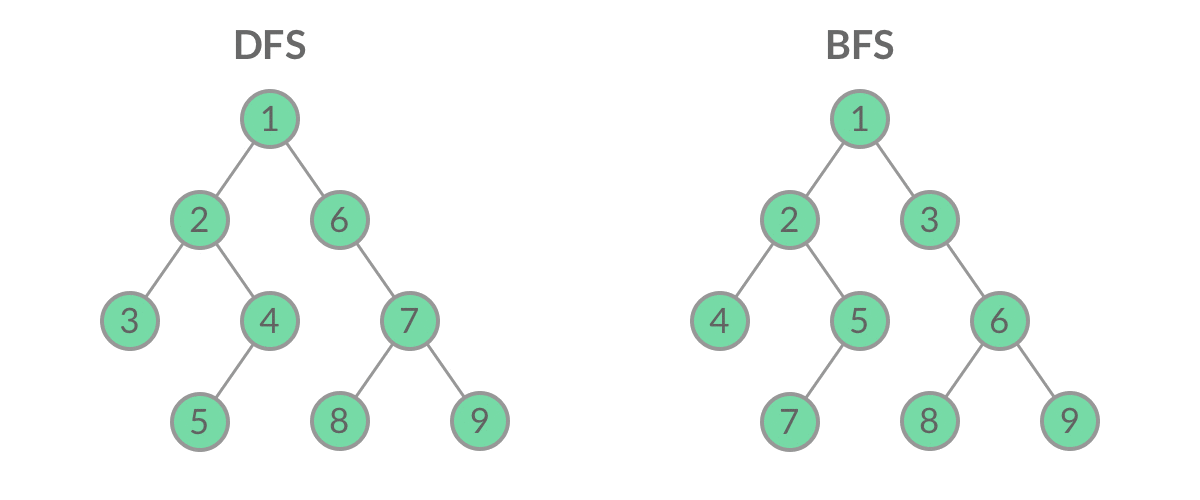
这个遍历顺序也是 BFS 能够用来解「层序遍历」、「最短路径」问题的根本原因。
层次遍历
给你一个二叉树,请你返回其按 层序遍历 得到的节点值。 (即逐层地,从左到右访问所有节点)。
示例:
二叉树:[3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回其层次遍历结果:
[
[3],
[9,20],
[15,7]
]
我们需要稍微修改一下BFS代码,在每一层遍历开始前,先记录队列中的结点数量 size(也就是这一层的结点数量),然后一口气处理完这一层的 size 个结点。
public List<List<Integer>> levelOrder(TreeNode root) {
List result = new LinkedList();
if(root ==null){
return result;
}
Queue<TreeNode> queue = new ArrayDeque();
queue.add(root);
while(!queue.isEmpty()){
int size = queue.size();
List<Integer> subResult = new LinkedList();
for (int i=0;i<size;i++){
TreeNode node = queue.poll();
subResult.add(node.val);
if(node.left!=null){
queue.add(node.left);
}
if(node.right!=null){
queue.add(node.right);
}
}
result.add(subResult);
}
return result;
}