一、容器基本概念
操作系统如何管理进程
- 进程可见、可相互通信
- 共享同一份文件系统
什么是容器
- 资源视图隔离
- 控制资源使用率
- 独立的文件系统
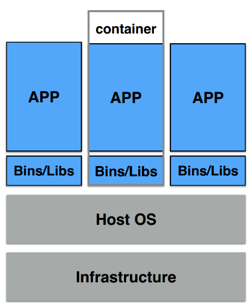
容器是一个视图隔离、资源可限制、独立文件系统的进程集合
- 资源视图隔离 – namespace
- 控制资源使用率 – cgroup 如2G内存大小;CPU使用个数等;
- 独立文件系统 – chroot
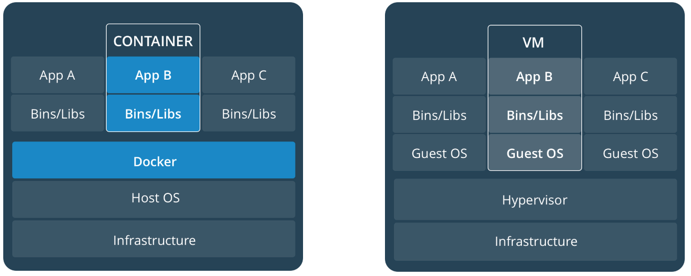
Container VS VM
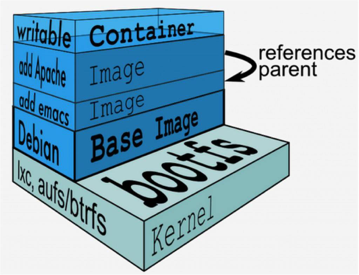
什么是容器镜像
运行容器所需要的所有文件集合
- 一个特殊的文件系统 – 程序、库、资源、配置
- Dockerfile – 描述镜像构建步骤
- 不同的层可以被其他镜像复用
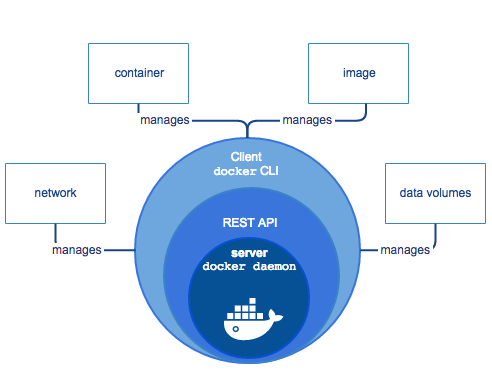
Docker
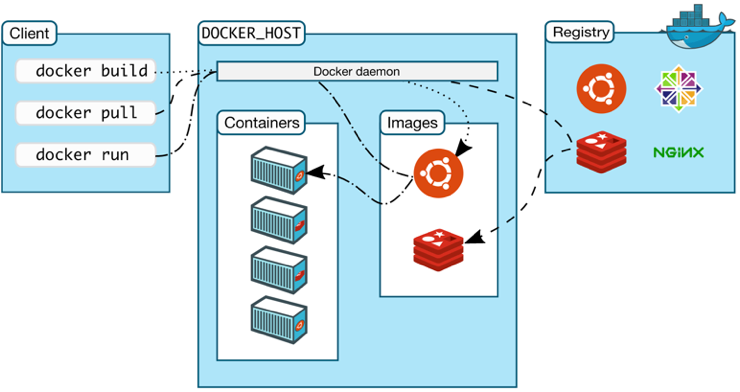
如何运行容器
二、Kubernetes核心概念
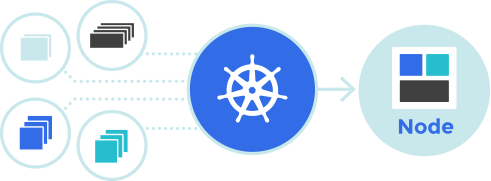
什么是Kubernetes
工业级容器编排平台
- Kubernetes 源于希腊语,意为“舵手”
- k8s 缩写,读音相近

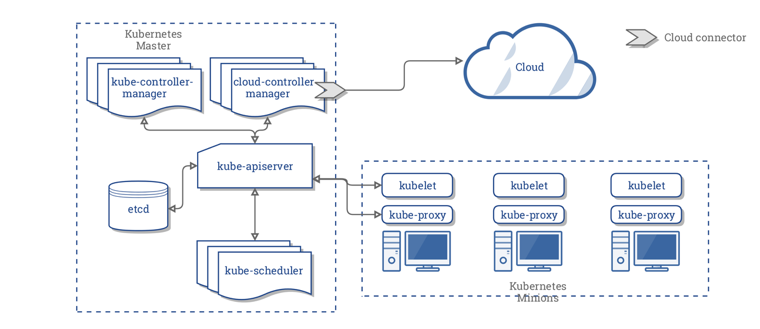
K8S架构
K8S架构 – 例子

K8S核心功能
- 服务发现与负载均衡
- 容器自动装箱
- 存储编排
- 自动容器恢复
- 自动发布与回滚
- 配置和密文管理
- 批量执行
- 水平伸缩
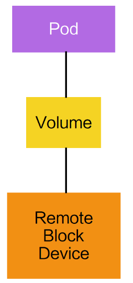
Pod
- 最小的调度以及资源单元
- 由一个或者多个容器组成
- 定义容器运行方式
- 提供给容器共享的运行环境(网络、进程空间)

Volume
- 声明在Pod中的容器可以访问的文件目录
- 可以被挂载在Pod中一个(或者多个)容器的指定路径下
- 支持多种后端存储抽象 – 本地存储、分布式存储、云存储
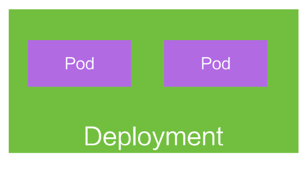
Deployment
- 定义一组Pod的副本数目、版本等
- 通过控制器(Controller)维护Pod的数目 – 自动恢复失败的Pod
- 通过控制器以指定的策略控制版本 – 滚动升级、回滚
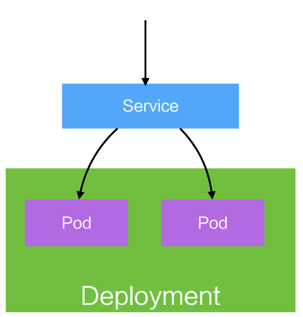
Service
- 提供访问一个或多个Pod实例的稳定访问地址
- 支持多种访问方式 – ClusterIp、NodePort、LoadBalancer
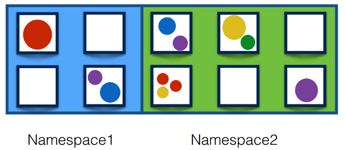
Namespaces
- 一个集群内部的逻辑隔离机制(鉴权、资源额度)
- 每个资源都属于一个Namespace
- 同一个Namespace的资源命名唯一
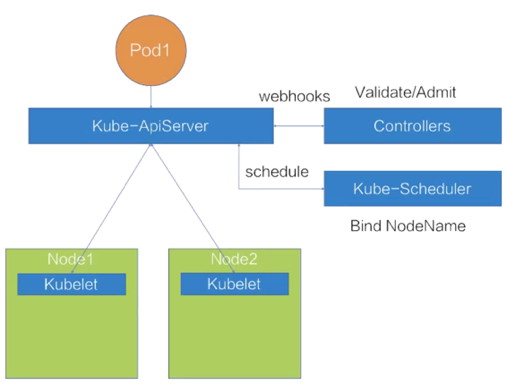
三、容器调度与管理
调度过程
- 最优Node
- 满足pod资源要求
- 满足pod特殊关系要求
- 满足Node限制条件要求
- 做到集群资源合理利用
调度器架构
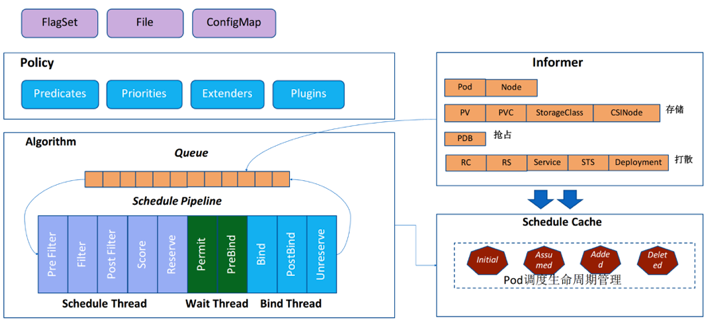
调度流程
- Predicates
- Priorities
Predicates
- 存储相关
- CheckVolumeBindingPred pvc和pv的binding校验
- NoDiskConflict 是否重复挂载
- Pod与Node匹配相关
- CheckNodeCondition node是否ready
- MathNodeSelector
- PodToleratesNodeTaints
- Pod与Pod匹配相关
- MatchInterPodAffinity PodAffinity 校验
- Pod打散相关
- EvenPodsSpread
Priorities
解决问题 – 碎片、容灾、水位、亲和、反亲和
- LeastRequestedPriority: 优先打散
- MostRequestedPriority: 优先堆叠
- RequestedResourceAllocation: 碎片率
- NodeAffinityPriority: Node亲和&反亲和
- InterPodAffinityPriority:Pod亲和&反亲和
基础调度能力
- 资源调度
- Resources:CPU/Memory/Storage/GPU
- Qos:Guaranteed/Burstable/BestEffort
- Resource Quota
- 关系调度
- PodAffinity/PodAntiAffinity:Pod与Pod关系
- NodeSelector/NodeAffinity:由Pod决定适合自己的Node
- Taint/Tolerations:限制调度到某些Node
资源调度用法
- Pod资源类型
- cpu
- memory
- 怎么用?
- Comtainer resources
- request/limit
- Cpu:1=1000m
resources:
limits:
cpu: 2
memory: 2000Mi
requests:
cpu: 500m
memory: 1000Mi
-
为什么会有request和limit?
- 什么是Pod QoS
- Quality of Service
-
三类QoS
- Guaranteed – 高,保障 CPU/Memory必须request=limit
- Burstable – 中,弹性 CPU/Memory必须request!=limit
- BestBestEffort – 低,尽力而为 所有资源request、limit必须都不填
-
隐性的QoS Class
-
怎么用?
-
调度器使用request进行调度
-
底层表现
- CPU 按照request划分权重 – cpu-manager-policy=static guaranteed整数会绑核
- Memory 按照QoS划分OOMScore
- Guarantted -998
- Burstable 2-999
- BestEffort 1000
-
Eviction
- 优先Evict BestEffort
如何满足Pod资源要求? -资源Quota
- 限制每个namespace资源用量
- 当Quota用超后会禁止创建
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu-demo
spec:
hard:
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
pods: "10"
如何满足Pod与Pod关系要求? -Pod亲和调度
PodAffinity 和 PodAntiAffinity
- Pod亲和调度 PodAffinity
- 必须和某些Pod调度在一起 requiredDuringSchedulingIgnoredDuringExecution
- 优先和某些Pod调度在一起 preferredDuringSchedulingIgnoredDuringExecution
- Pod反亲和调度 PodAntiAffinity
- 禁止和某些Pod调度到一起
- 优先不和某些Pod调度到一起
- Operator In/NotIn/Exists/DoesNoExist
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: kubernetes.io/hostname
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: kubernetes.io/hostname
如何满足Pod与Node关系要求? -Node亲和调度
NodeSelector 和 NodeAffinity
- NodeSelector
- 必须调度到带有标签的Node
- NodeAffinity
- 必须调度到某些Node上 requiredDuringSchedulingIgnoredDuringExecution
- 优先调度到某些Node上 preferredDuringSchedulingIgnoredDuringExecution
- Operator
- In/NotIn/Exists/DoesNotExist/Gt/Lt
spec:
nodeSelector:
zone: m6
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- preference:
matchExpressions:
- key: service-type
operator: In
values:
- order
weight: 1
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: service-type
operator: In
values:
- order
- product
如何限制调度到某些Node? -Node 污点/容忍
Taints 和 Tolerations
- Node Taints
- 一个node可以有多个Taints
- Effect
- NoSchedule 除非Pod明确声明可以容忍这个Taint,否则禁止调度
- PreferNoSchedule 如果没有声明容忍,尽量不要调度
- NoExecute 禁止调度并evict没有对应toleration的Pod
- Pod Tolerations
- 一个node可以有多个Tolerations
- Effect
- Operator
- Exists/Equal
spec:
taints:
- effect: NoSchedule
key: onlytest
value: "yes"
spec:
tolerations:
- key: "onlytest"
operator: "Equal"
value: "yes"
effect: "NoSchedule"
高级调度能力
- 优先级调度和抢占
- Priority
- Preemption
如何做到集群资源合理利用? – 优先级调度
-
资源不够时怎么办?
- FIFO – 简单、公平
- Priority – 符合日常公司业务特征
-
PodPriority 和Preemptions
- V1.14 – stable
- default is ons
如何做到集群资源合理利用? – 优先级调度配置
- 怎么使用
- 创建Priority
- 为Pod配置上不同的priorityClassName
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 10000
globalDefault: false
description: "This priority is high."
spec:
priorityClassName: high-priority
如何做到集群资源合理利用? – 优先级调度过程
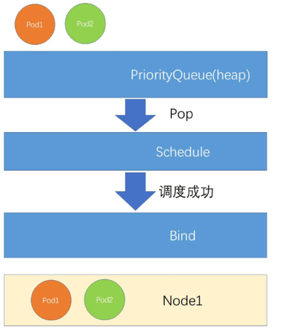
发生在Pending Pod出队列开始调度
- Pod1和Pod2先后进入调度队列
- 当进行一轮调度时,PriorityQueue会优先Pop
- 优先级更大的Pod1出队列调度
- 调度成功后,对Pod1进行Bind,开始下一轮调度Pod2
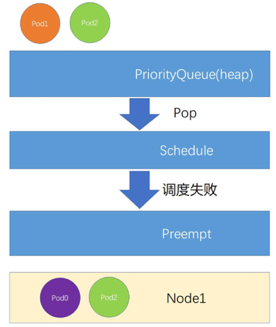
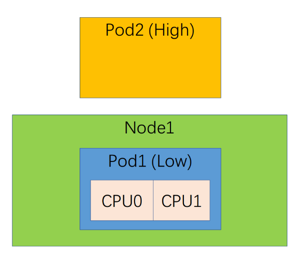
如何做到集群资源合理利用? – 优先级抢占过程
发生在调度失败
- Pod2先进行调度,调度成功后分配至Node1上运行
- 之后Pod1再进行调度,由于Node1资源不足出现了调度失败,
- 此时进入抢占流程
- 在经过抢占算法计算后,选中了Pod2作为Pod1的让渡者
- 驱逐Node1上运行的Pod2, 并将Pod1调度至Node1