首先给出 TreeNode 的定义,我们将会在后续的代码实现中使用它。
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) {
val = x;
}
}
二叉树的所有路径
给定一个二叉树,返回所有从根节点到叶子节点的路径。
示例
输入:
1
/ \
2 3
\
5
输出: ["1->2->5", "1->3"]
解释: 所有根节点到叶子节点的路径为: 1->2->5, 1->3
题解
二叉树的所有路径,该算法是其他算法的基础。
递归
在递归遍历二叉树时,需要考虑当前的节点和它的孩子节点。
如果当前的节点不是叶子节点,则在当前的路径末尾添加该节点,并递归遍历该节点的每一个孩子节点。
如果当前的节点是叶子节点,则在当前的路径末尾添加该节点后,就得到了一条从根节点到叶子节点的路径,可以把该路径加入到答案中。
public List<String> binaryTreePaths(TreeNode root) {
LinkedList<String> paths = new LinkedList();
construct_paths(root, "", paths);
return paths;
}
public void construct_paths(TreeNode root, String path, LinkedList<String> paths) {
if (root != null) {
path += Integer.toString(root.val);
if ((root.left == null) && (root.right == null)) // 当前节点是叶子节点
paths.add(path); // 把路径加入到答案中
else {
path += "->"; // 当前节点不是叶子节点,继续递归遍历
construct_paths(root.left, path, paths);
construct_paths(root.right, path, paths);
}
}
}
复杂度分析
- 时间复杂度:每个节点只会被访问一次,因此时间复杂度为 O(N),其中 N 表示节点数目。
- 空间复杂度:O(N)。这里不考虑存储答案 paths 使用的空间,仅考虑额外的空间复杂度。额外的空间复杂度为递归时使用的栈空间,在最坏情况下,当二叉树中每个节点只有一个孩子节点时,递归的层数为 N,此时空间复杂度为 O(N)。在最好情况下,当二叉树为平衡二叉树时,它的高度为log(N),此时空间复杂度为 O(log(N))。
迭代
上面的算法也可以使用迭代(宽度优先搜索)的方法实现。
我们维护一个队列,存储节点以及根到该节点的路径。
一开始这个队列里只有根节点。在每一步迭代中,我们取出队列中的首节点,如果它是一个叶子节点,则将它对应的路径加入到答案中。
如果它不是一个叶子节点,则将它的所有孩子节点加入到队列的末尾。
当队列为空时,迭代结束。
public List<String> binaryTreePaths(TreeNode root) {
LinkedList<String> paths = new LinkedList();
if (root == null)
return paths;
LinkedList<TreeNode> node_stack = new LinkedList();
LinkedList<String> path_stack = new LinkedList();
node_stack.add(root);
path_stack.add(Integer.toString(root.val));
TreeNode node;
String path;
while (!node_stack.isEmpty()) {
node = node_stack.pollLast();
path = path_stack.pollLast();
if ((node.left == null) && (node.right == null))
paths.add(path);
if (node.left != null) {
node_stack.add(node.left);
path_stack.add(path + "->" + Integer.toString(node.left.val));
}
if (node.right != null) {
node_stack.add(node.right);
path_stack.add(path + "->" + Integer.toString(node.right.val));
}
}
return paths;
}
求根到叶子节点数字之和
给定一个二叉树,它的每个结点都存放一个 0-9 的数字,每条从根到叶子节点的路径都代表一个数字。
例如,从根到叶子节点路径 1->2->3 代表数字 123。
计算从根到叶子节点生成的所有数字之和。
示例
输入: [1,2,3]
1
/ \
2 3
输出: 25
解释:
从根到叶子节点路径 1->2 代表数字 12.
从根到叶子节点路径 1->3 代表数字 13.
因此,数字总和 = 12 + 13 = 25.
题解
如果知道怎么找到所有路径,至少可以先找到所有路径然后将路径转数字求和即可。这也是一种解法。
这道题的解题思路和求二叉树所有路径类似。
仍旧是关于recursion的问题,百变不离其宗,之前是保存每一个path,现在是对每一个path进行数学计算,都是要进行遍历才可以实现。
注意两个点:
- 一个是关于数学的计算,旧值要✖️10+新值,才能达到题目要求。
- 一个是关于返回值,可以设立变量求出每个path的值,最后求和;也可以直接在return的时候直接返回即可,更简便。
思路:
- 并不是简单地node.val相加而已,而是像string一样“接”在后面形成新的数。
- 如果此node是leaf,那我们直接返回现在的sum即可;但如果有的node仅有一个child node(对于BST而言,有两个child node才是leaf),那我们必须进行下去。
- 先计算左枝,到头后,再倒退,继续右枝,不断重复,将左右结果叠加返回即可,即recursion call。
public int sumNumbers(TreeNode root) {
if(root == null){
return 0;
}
return allSum(root, 0);
}
private int allSum(TreeNode node, int curPath){
if(node == null){
return 0;
}
curPath = curPath * 10 + node.val;
if(node.left == null && node.right == null){
return curPath;
}
return allSum(node.left, curPath) + allSum(node.right, curPath);
}
路径总和
给定一个二叉树和一个目标和,找到所有从根节点到叶子节点路径总和等于给定目标和的路径。
示例
给定如下二叉树,以及目标和 sum = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ / \
7 2 5 1
返回:
[
[5,4,11,2],
[5,8,4,5]
]
题解
思路:
- 要建立list组成的list来存最终的result,要建立list去存当前的这个路径。
- 接下来思路与之前近乎相同,采用recursion的方法,先遍历左侧,如果没有满足条件且是leaf,则倒退一个node,继续右枝(如果有的话)。
- 将每一个遍历到的node放入curPath,然后改变条件至sum-node.val。
- 如果满足条件,则存下当前的一个list,也就是curPath;如果不满足条件,则将sum改为sum-node.val继续进行recursion。
- 最重要的一点,当我们到达了某一个leaf的时候,我们发现当前path并不满足和为sum的时候,我们在倒退会上一个node的同时,要在curPath中清除当前节点!!!!
public List<List<Integer>> pathSum(TreeNode root, int sum) {
List<List<Integer>> result = new LinkedList<>();
List<Integer> curPath = new LinkedList<>();
recur(result, curPath, root, sum);
return result;
}
private void recur(List<List<Integer>> result, List<Integer> curPath, TreeNode curNode, int sum){
if(curNode == null){
return;
}
curPath.add(curNode.val);
if(curNode.val == sum && curNode.left == null && curNode.right == null){
result.add(new ArrayList<>(curPath));
}else{
recur(result, curPath, curNode.left, sum - curNode.val);
recur(result, curPath, curNode.right, sum - curNode.val);
}
curPath.remove(curPath.size() - 1);
}
路径总和2
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。
示例
给定如下二叉树,以及目标和 sum = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ \
7 2 1
返回 true, 因为存在目标和为 22 的根节点到叶子节点的路径 5->4->11->2。
题解
递归
最直接的方法就是利用递归,遍历整棵树:如果当前节点不是叶子,对它的所有孩子节点,递归调用 hasPathSum 函数,其中 sum 值减去当前节点的权值;如果当前节点是叶子,检查 sum 值是否为 0,也就是是否找到了给定的目标和。
public boolean hasPathSum(TreeNode root, int sum) {
if (root == null)
return false;
sum -= root.val;
if ((root.left == null) && (root.right == null))
return (sum == 0);
return hasPathSum(root.left, sum) || hasPathSum(root.right, sum);
}
迭代
我们可以用栈将递归转成迭代的形式。
深度优先搜索在除了最坏情况下都比广度优先搜索更快。最坏情况是指满足目标和的 root->leaf 路径是最后被考虑的,这种情况下深度优先搜索和广度优先搜索代价是相通的。
利用深度优先策略访问每个节点,同时更新剩余的目标和。
所以我们从包含根节点的栈开始模拟,剩余目标和为 sum – root.val。
然后开始迭代:弹出当前元素,如果当前剩余目标和为 0 并且在叶子节点上返回 True;如果剩余和不为零并且还处在非叶子节点上,将当前节点的所有孩子以及对应的剩余和压入栈中。
public boolean hasPathSum(TreeNode root, int sum) {
if (root == null)
return false;
LinkedList<TreeNode> node_stack = new LinkedList();
LinkedList<Integer> sum_stack = new LinkedList();
node_stack.add(root);
sum_stack.add(sum - root.val);
TreeNode node;
int curr_sum;
while ( !node_stack.isEmpty() ) {
node = node_stack.pollLast();
curr_sum = sum_stack.pollLast();
if ((node.right == null) && (node.left == null) && (curr_sum == 0))
return true;
if (node.right != null) {
node_stack.add(node.right);
sum_stack.add(curr_sum - node.right.val);
}
if (node.left != null) {
node_stack.add(node.left);
sum_stack.add(curr_sum - node.left.val);
}
}
return false;
}
二叉树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]
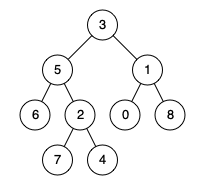
示例
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出: 3
解释: 节点 5 和节点 1 的最近公共祖先是节点 3。
题解
递归
思路和算法
我们递归遍历整棵二叉树,定义 fx表示 x 节点的子树中是否包含 p 节点或 q 节点,如果包含为 true,否则为 false。
那么符合条件的最近公共祖先 x 一定满足如下条件:
(flson && frson)||((x==p||x==q)&&(flson || frson))
其中 lson 和 rson 分别代表 x 节点的左孩子和右孩子。
初看可能会感觉条件判断有点复杂,我们来一条条看:
(flson && frson)说明左子树和右子树均包含 p 节点或 q 节点,如果左子树包含的是 p 节点,那么右子树只能包含 q 节点,反之亦然,因为 p 节点和 q 节点都是不同且唯一的节点,因此如果满足这个判断条件即可说明 x 就是我们要找的最近公共祖先。
再来看第二条判断条件,((x==p||x==q)&&(flson || frson)) 这个判断条件即是考虑了 x 恰好是 p 节点或 q 节点且它的左子树或右子树有一个包含了另一个节点的情况,因此如果满足这个判断条件亦可说明 x 就是我们要找的最近公共祖先。
你可能会疑惑这样找出来的公共祖先深度是否是最大的。
其实是最大的,因为我们是自底向上从叶子节点开始更新的,所以在所有满足条件的公共祖先中一定是深度最大的祖先先被访问到,且由于 fx表本身的定义很巧妙,在找到最近公共祖先 x 以后, fx表按定义被设置为 true ,即假定了这个子树中只有一个 p 节点或 q 节点,因此其他公共祖先不会再被判断为符合条件。
class Solution {
private TreeNode ans;
public Solution() {
this.ans = null;
}
private boolean dfs(TreeNode root, TreeNode p, TreeNode q) {
if (root == null) return false;
boolean lson = dfs(root.left, p, q);
boolean rson = dfs(root.right, p, q);
if ((lson && rson) || ((root.val == p.val || root.val == q.val) && (lson || rson))) {
ans = root;
}
return lson || rson || (root.val == p.val || root.val == q.val);
}
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
this.dfs(root, p, q);
return this.ans;
}
}
存储父节点
这种解法比较好理解。
思路
我们可以用哈希表存储所有节点的父节点,然后我们就可以利用节点的父节点信息从 p 结点开始不断往上跳,并记录已经访问过的节点,再从 q 节点开始不断往上跳,如果碰到已经访问过的节点,那么这个节点就是我们要找的最近公共祖先。
算法
- 从根节点开始遍历整棵二叉树,用哈希表记录每个节点的父节点指针。
- 从 p 节点开始不断往它的祖先移动,并用数据结构记录已经访问过的祖先节点。
- 同样,我们再从 q 节点开始不断往它的祖先移动,如果有祖先已经被访问过,即意味着这是 p 和 q 的深度最深的公共祖先,即 LCA 节点。
class Solution {
Map<Integer, TreeNode> parent = new HashMap<Integer, TreeNode>();
Set<Integer> visited = new HashSet<Integer>();
public void dfs(TreeNode root) {
if (root.left != null) {
parent.put(root.left.val, root);
dfs(root.left);
}
if (root.right != null) {
parent.put(root.right.val, root);
dfs(root.right);
}
}
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
dfs(root);
while (p != null) {
visited.add(p.val);
p = parent.get(p.val);
}
while (q != null) {
if (visited.contains(q.val)) {
return q;
}
q = parent.get(q.val);
}
return null;
}
}
二叉搜索树的最近公共祖先
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]
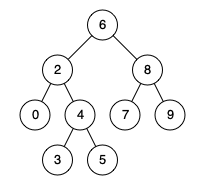
示例
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8
输出: 6
解释: 节点 2 和节点 8 的最近公共祖先是 6。
题解
我们来复习一下二叉搜索树(BST)的性质:
- 节点 N 左子树上的所有节点的值都小于等于节点 N 的值
- 节点 N 右子树上的所有节点的值都大于等于节点 N 的值
- 左子树和右子树也都是 BST
递归
思路
节点 p,q 的最近公共祖先(LCA)是距离这两个节点最近的公共祖先节点。在这里 最近 考虑的是节点的深度。
下面这张图能帮助你更好的理解 最近 这个词的含义。
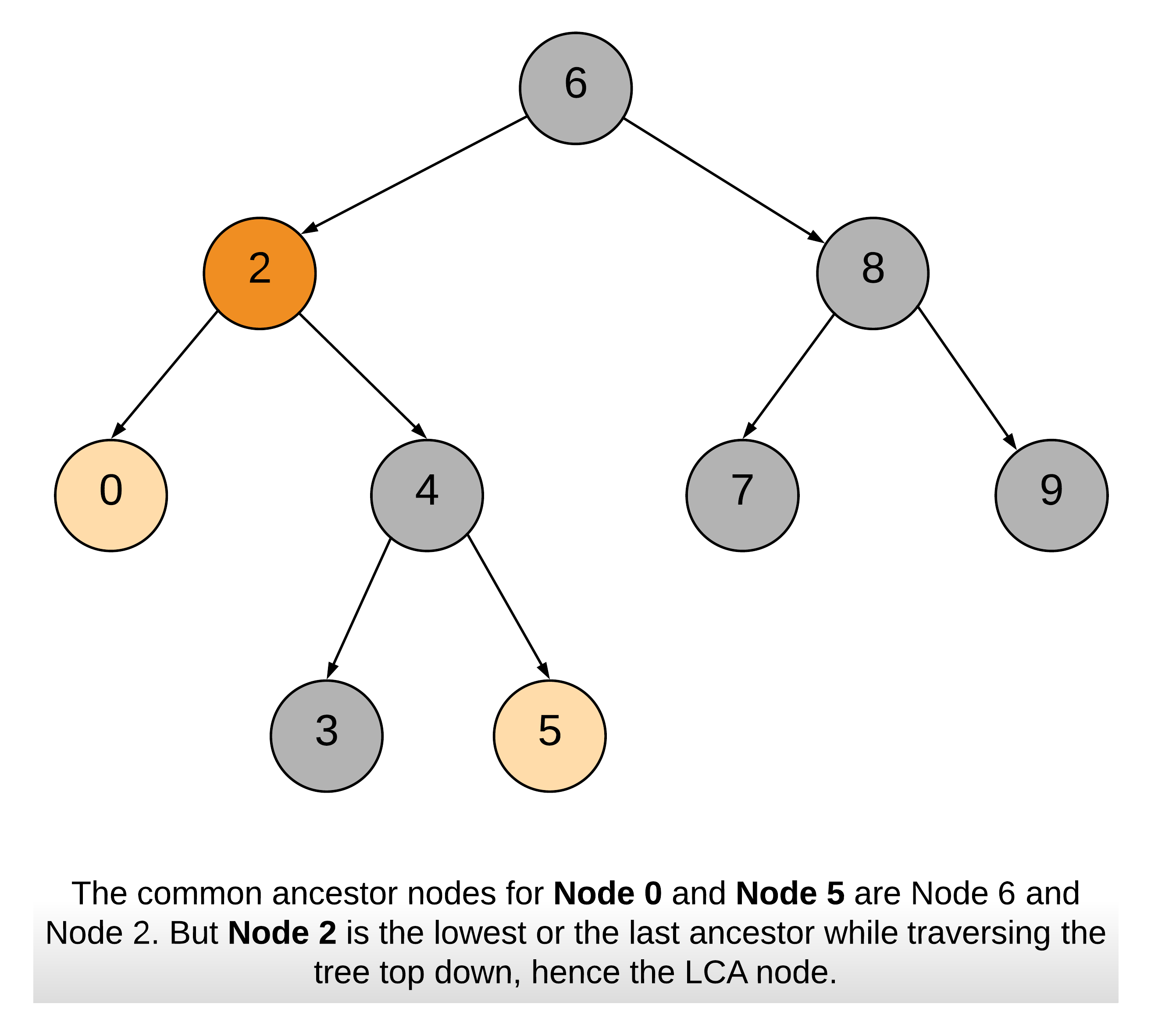
笔记:p 和 q 其中的一个在 LCA 节点的左子树上,另一个在 LCA 节点的右子树上。
也有可能是下面这种情况:
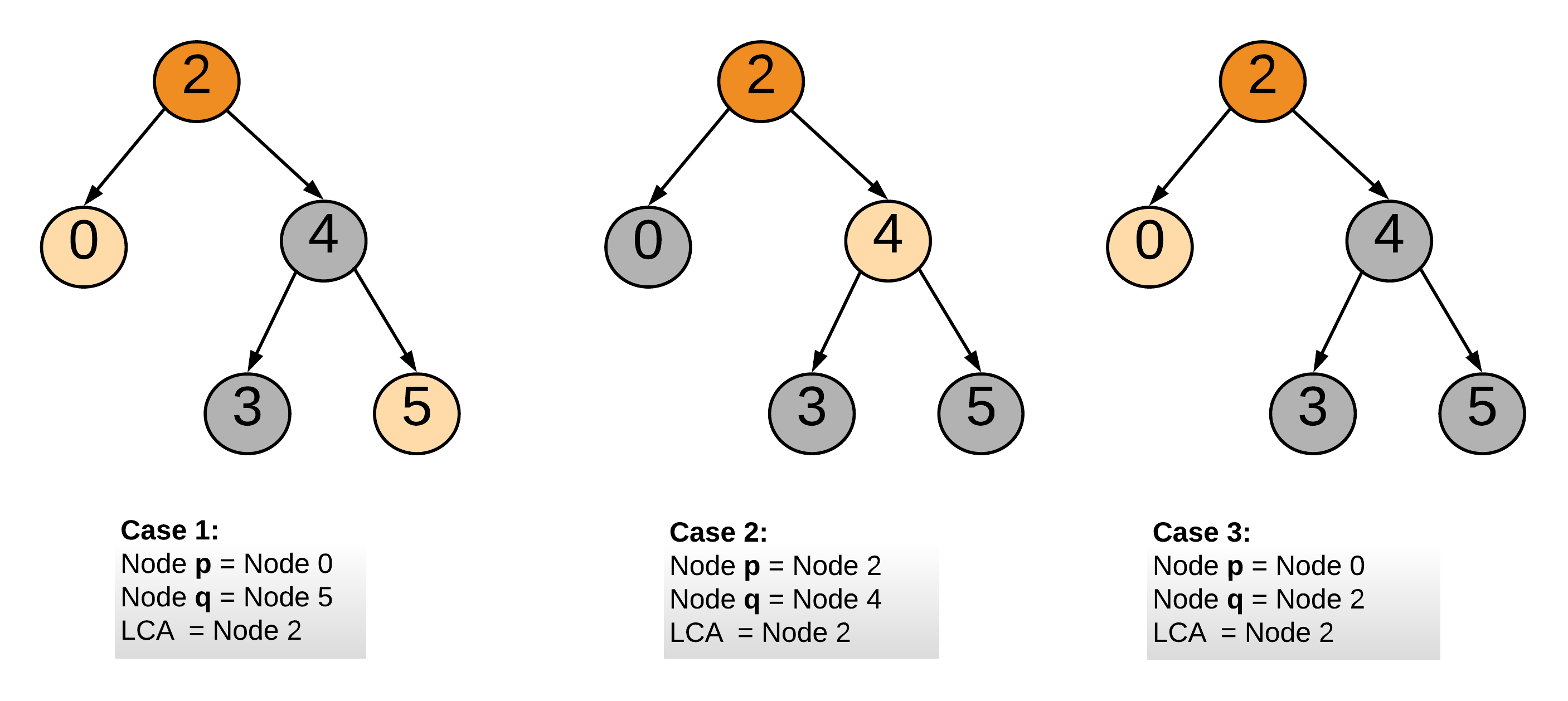
算法
- 从根节点开始遍历树
- 如果节点 p 和节点 q 都在右子树上,那么以右孩子为根节点继续 1 的操作
- 如果节点 p 和节点 q 都在左子树上,那么以左孩子为根节点继续 1 的操作
- 如果条件 2 和条件 3 都不成立,这就意味着我们已经找到节 p 和节点 q的 LCA 了
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
// Value of current node or parent node.
int parentVal = root.val;
// Value of p
int pVal = p.val;
// Value of q;
int qVal = q.val;
if (pVal > parentVal && qVal > parentVal) {
// If both p and q are greater than parent
return lowestCommonAncestor(root.right, p, q);
} else if (pVal < parentVal && qVal < parentVal) {
// If both p and q are lesser than parent
return lowestCommonAncestor(root.left, p, q);
} else {
// We have found the split point, i.e. the LCA node.
return root;
}
}
迭代
这个方法递归很接近。唯一的不同是,我们用迭代的方式替代了递归来遍历整棵树。
由于我们不需要回溯来找到 LCA 节点,所以我们是完全可以不利用栈或者是递归的。实际上这个问题本身就是可以迭代的,我们只需要找到分割点就可以了。这个分割点就是能让节点 p 和节点 q 不能在同一颗子树上的那个节点,或者是节点 p 和节点 q 中的一个,这种情况下其中一个节点是另一个节点的父亲节点。
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
// Value of p
int pVal = p.val;
// Value of q;
int qVal = q.val;
// Start from the root node of the tree
TreeNode node = root;
// Traverse the tree
while (node != null) {
// Value of ancestor/parent node.
int parentVal = node.val;
if (pVal > parentVal && qVal > parentVal) {
// If both p and q are greater than parent
node = node.right;
} else if (pVal < parentVal && qVal < parentVal) {
// If both p and q are lesser than parent
node = node.left;
} else {
// We have found the split point, i.e. the LCA node.
return node;
}
}
return null;
}
最小公共区域
给你一些区域列表 regions ,每个列表的第一个区域都包含这个列表内所有其他区域。
很自然地,如果区域 X 包含区域 Y ,那么区域 X 比区域 Y 大。
给定两个区域 region1 和 region2 ,找到同时包含这两个区域的 最小 区域。
如果区域列表中 r1 包含 r2 和 r3 ,那么数据保证 r2 不会包含 r3 。
数据同样保证最小公共区域一定存在。
示例
输入:
regions = [["Earth","North America","South America"],
["North America","United States","Canada"],
["United States","New York","Boston"],
["Canada","Ontario","Quebec"],
["South America","Brazil"]],
region1 = "Quebec",
region2 = "New York"
输出:"North America"
题解
思路
可以转化为求二叉树的最近公共祖先
不用构造树,仅需使用hash map 构建 子 -> 父 的关系即可
算法
1.将region和所属区域重新构造map
2.从底向上查找region的祖先,并记录到list中
3.遍历某个region的祖先列表,看在第二个region祖先列表中是否存在,如果存在,则是第一个共同的祖先。
public String findSmallestRegion(List<List<String>> regions, String region1, String region2) {
//保存region1的所有祖先节点。
//regin02的第一个出现在region01中的祖先节点,就是最近公共祖先
HashMap<String,String> ance=new HashMap<>();//<chard,parent>
for(List<String> oneRegin:regions){
String parent=oneRegin.get(0);
for(int i=1;i<oneRegin.size();i++) ance.put(oneRegin.get(i),parent);
}
//取出第一个区域的所有祖先
HashSet<String> ances1=new HashSet<>();
while(region1!=null) {
ances1.add(region1);
region1=ance.get(region1);//get his parent;
}
//查找第二个的祖先中第一次出现在ances1中。
while(!ances1.contains(region2))region2=ance.get(region2);
return region2;
}
二叉树中的最大路径和
给定一个非空二叉树,返回其最大路径和。
本题中,路径被定义为一条从树中任意节点出发,达到任意节点的序列。该路径至少包含一个节点,且不一定经过根节点。
示例
输入: [1,2,3]
1
/ \
2 3
输出: 6
题解
递归
思路
首先,考虑实现一个简化的函数 max_gain(node) ,参数是一个顶点,计算它及其子树的最大贡献。
换句话说,就是计算包含这个顶点的最大权值路径。

因此如果可知最后的最大路径和包含 root ,那么答案就是 max_gain(root)。
然而,最大路径可能并不包括根节点,比如下面的这棵树:
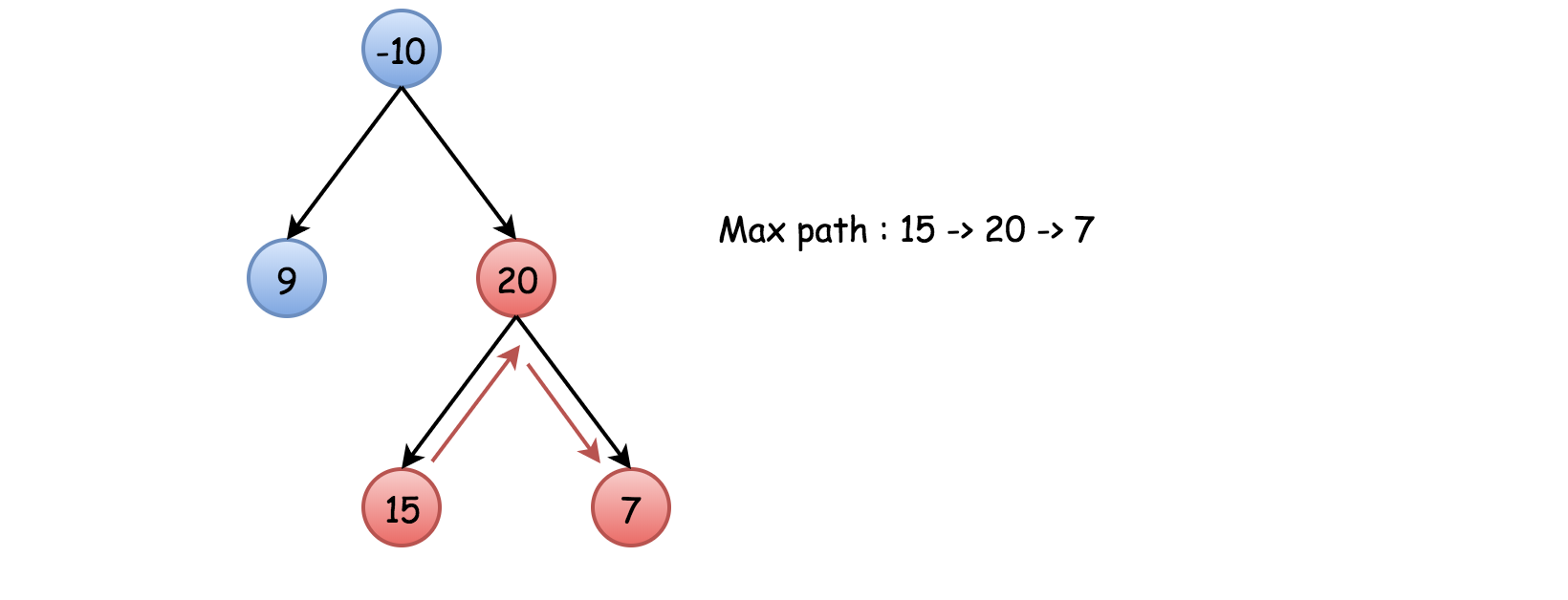
这意味着我们要修改上面的函数,在每一步都检查哪种选择更好:是继续当前路径或者以当前节点作为最高节点计算新的路径。
算法
现在万事俱备,只欠算法。
- 初始化 max_sum 为最小可能的整数并调用函数 max_gain(node = root)。
- 实现 max_gain(node) 检查是继续旧路径还是开始新路径:
- 边界情况:如果节点为空,那么最大权值是 0 。
- 对该节点的所有孩子递归调用 max_gain,计算从左右子树的最大权值:left_gain = max(max_gain(node.left), 0) 和 right_gain = > max(max_gain(node.right), 0)。
- 检查是维护旧路径还是创建新路径。创建新路径的权值是:price_newpath = node.val + left_gain + right_gain,当新路径更好的时候更新 max_sum。
- 对于递归返回的到当前节点的一条最大路径,计算结果为:node.val + max(left_gain, right_gain)。
class Solution {
int max_sum = Integer.MIN_VALUE;
public int maxPathSum(TreeNode root) {
max_gain(root);
return max_sum;
}
public int max_gain(TreeNode node) {
if (node == null) return 0;
// max sum on the left and right sub-trees of node
int left_gain = Math.max(max_gain(node.left), 0);
int right_gain = Math.max(max_gain(node.right), 0);
// the price to start a new path where `node` is a highest node
int price_newpath = node.val + left_gain + right_gain;
// update max_sum if it's better to start a new path
max_sum = Math.max(max_sum, price_newpath);
// for recursion :
// return the max gain if continue the same path
return node.val + Math.max(left_gain, right_gain);
}
}
最长同值路径
给定一个二叉树,找到最长的路径,这个路径中的每个节点具有相同值。 这条路径可以经过也可以不经过根节点。
注意: 两个节点之间的路径长度由它们之间的边数表示。
示例
输入:
1
/ \
4 5
/ \ \
4 4 5
输出:
2
题解
递归
思路
我们可以将任何路径(具有相同值的节点)看作是最多两个从其根延伸出的箭头。
具体地说,路径的根将是唯一节点,因此该节点的父节点不会出现在该路径中,而箭头将是根在该路径中只有一个子节点的路径。
然后,对于每个节点,我们想知道向左延伸的最长箭头和向右延伸的最长箭头是什么?我们可以用递归来解决这个问题。
算法
令 arrow_length(node) 为从节点 node 延伸出的最长箭头的长度。如果 node.Left 存在且与节点 node 具有相同的值,则该值就会是 1 + arrow_length(node.left)。在 node.right 存在的情况下也是一样。
当我们计算箭头长度时,候选答案将是该节点在两个方向上的箭头之和。我们将这些候选答案记录下来,并返回最佳答案。
class Solution {
int ans;
public int longestUnivaluePath(TreeNode root) {
ans = 0;
arrowLength(root);
return ans;
}
public int arrowLength(TreeNode node) {
if (node == null) return 0;
int left = arrowLength(node.left);
int right = arrowLength(node.right);
int arrowLeft = 0, arrowRight = 0;
if (node.left != null && node.left.val == node.val) {
arrowLeft += left + 1;
}
if (node.right != null && node.right.val == node.val) {
arrowRight += right + 1;
}
ans = Math.max(ans, arrowLeft + arrowRight);
return Math.max(arrowLeft, arrowRight);
}
}