应该如何选择多少位的JVM呢?
32位JVM的寻址空间只有4G(232), 也就是你的java进程最大只能使用4G内存(因为有其他开销,实际远小于4G);而64位JVM的寻址空间最大有264,
差不多可以理解为无限大。
64位的JVM性能要比32位的JVM要高?
其实恰恰相反,64位JVM的寻址空间更大了,但是会带来性能的损耗;同样的应用,运行在64位JVM上 比起 运行在32位JVM上 会有0~20%的性能损耗(取决于应用里面指针的数量)。
其实从名字上我们可以就可以区分,64位JVM,他的每一个native指针都占用64位(即64bit,也就是8字节)。32位JVM则只有4字节。 加载这些额外的字节也自然会影响内存的占用。
指针的寻址原理
假如我们这里有3个对象A、B、C,他们的大小分别为8、16、8字节,并且在内存中连续存储。

指针用 内存位置 来标记对象在内存中的位置:
A:00000000 00000000 00000000 00000000 (十进制表示:0)
B:00000000 00000000 00000000 00001000 (十进制表示:8)
C:00000000 00000000 00000000 00011000 (十进制表示:24)
从上面可以看出32位的指针,满打满算也只能存储232, 约4GB的内存地址。如果是64位的指针,就能表示264, 上面说的可以理解为无限大,如果你有听过 国际象棋盘与麦粒 的故事就知道,它肯定能满足需求,甚至感觉还有点浪费。
指针压缩
既然64位指针用来存储太浪费了,有什么更好的办法可以在32位的限制下表示更多的内存地址吗?这时,我们发现对象A、B、C大小都是8字节的整数倍,即8是他们对象大小的最大公约数!
我这边就不卖关子,直接说答案,我们可以借助索引来标识。用 8位内存地址偏移量 代表 1索引那么A的位置就可以标识为 索引0,B为 索引1,C为 索引3。

指针用 索引 来标记对象在内存中的位置:
A:00000000 00000000 00000000 00000000 (十进制表示:0)
B:00000000 00000000 00000000 00000001 (十进制表示:1)
C:00000000 00000000 00000000 00000011 (十进制表示:3)
加入索引这一概念是为了方便理解;实际上JVM是通过读取时左移3位,存储时右移3位来完成的。也就是说原本可表示4GB的内存地址,因为1索引表示8个内存地址偏移量,现在可以表示最高存储32GB的内存地址了
Java对象的大小为什么必须是8字节的整数倍?
现在大多数计算机都是高效的64位处理器,顾名思义,一次能处理64位的指令,即8个字节的数据,HotSpot VM的自动内存管理系统也就遵循了这个要求,Java对象的大小就必须是8字节的整数倍,这样子性能更高,处理更快。
JVM如何保证Java对象的大小都是8字节的整数倍?
用一个普通的Java对象举个简单的栗子?
在JVM中,Java对象保存在堆中,由三部分组成:
1.对象头 (Object Header)
2.示例数据(Instance Data)
3.对齐填充(Padding)
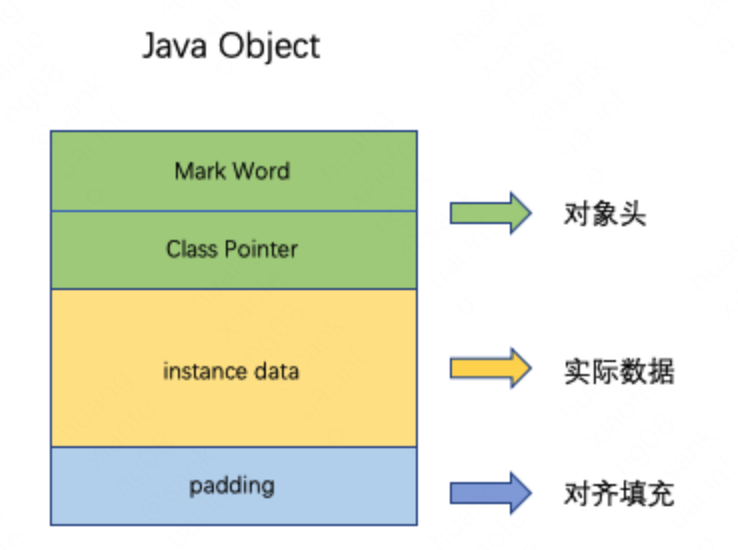
如果你还不了解的话也没关系,我们讨论的只牵扯到最后一个部分,也就是 对齐填充。对象可以有对齐填充,也可以没有;如果一个对象的前两部分所占大小不是8字节的整数倍,比如12字节,那么对齐填充会以此来填充对象大小到8字节的整数倍,即对齐填充占4字节,java对象一共16字节。
对齐填充:8字节的倍数就由我来组成!
Don’t Cross 32 GB!
Don’t Cross 32 GB。是因为当JVM堆少于32G时,HotSpot虚拟机会启用一个压缩对象指针。而如果超过32G,这个压缩对象指针就会失效。那么,纠结这个临界值的精确值是多大呢?开启压缩指针相比没有开启,能节省多少内存呢?让我们一探究竟!
32位的操作系统,最大只支持4G内存(即2^32)。当然,对于当下来说,32位服务器应该是绝种了,所以本文讨论的是64位操作系统。对于64位操作系统来说,理论上分配的堆可以非常非常大。但是,64位指针的开销就意味着有更多的浪费空间,这仅仅是因为指针更大。比浪费空间更糟糕的是,64位指针在主内存和多级缓存之间移动数据的时候,还会消费更多的带宽。
Java用”compressed oops”术解决了这个问题,指针不再是指向内存中精确位置,,而是对象的偏移量(原文: Instead of pointing at exact byte locations in memory, the pointers reference object offsets)。这就意味着,32位指针能引用232个对象(大约43亿个对象),而不是引用总计232个字节大小对象。所以,堆大小直到32G左右还能保持32位指针。
一旦你越过这个32G–一个具有魔法般的数值。指针将切回到普通的对象指针。每个指针变大,意味着需要更多的CPU,内存和带宽,真正用来保持对象的内存就会更少。这就可能导致一种奇怪的现象,使用compressed oops的32G的堆和40~50G没有使用compressed oops的堆保存的对象数量是一样的。
这个事实告诉我们:即使你有多余的内存,也应该尽量避免超过32G这个界限。它会浪费内存,降低CPU性能,并且大堆情况下GC表现也一般般。更麻烦的是,那么大的堆,DUMP分析将是一件极其痛苦,极其麻烦的事情。相信我,你一定不想碰到那种局面。
32G是个近似值,这个临界值跟JVM和平台有关。如果不想精确设置的话,31G是个决定安全的数值,31G肯定默认开启compressed oops。我们可以通过增加JVM参数-XX:+PrintFlagsFinal,验证UseCompressedOops的值,从而得知,到底是不是真的开启了压缩指针,还是压缩指针失效!
土豪我有1T内存?
JVM大堆的缺点太多了;
- 超过32G压缩指针失效;
- DUMP分析将是灾难;
- 堆越大,GC表现越差;
建议:开多个32G的JVM实例。4个32G的JVM实例绝对比1个128G实例表现要好。